

利用 GPU 伺服器本地磁碟打造「第 0 層」受保護可流動儲存,實現 100 倍 Checkpoint 效能提升
儘管企業級 NVMe 閃存價格持續下滑,但仍不便宜,尤其是在需大量儲存容量的情況下。然而,許多組織實際上擁有數百 TB 甚至 PB 等級的閒置儲存空間。為何會這樣?
利用 GPU 伺服器本地磁碟打造「第 0 層」受保護可流動儲存,實現 100 倍 Checkpoint 效能提升
GPU 伺服器本地磁碟:被忽視的寶貴資源
儘管企業級 NVMe 閃存價格持續下滑,但仍不便宜,尤其是在需大量儲存容量的情況下。然而,許多組織實際上擁有數百 TB 甚至 PB 等級的閒置儲存空間。為何會這樣?
若您購置一台(甚至一千台!)GPU 伺服器,它們很可能至少搭載數顆 NVMe SSD。以今日購買 NVIDIA DGX H200 或 B200 為例,無論是否需要,它們皆預載 8 顆 3.84TB 的 U.2 NVMe SSD。其他品牌雖提供彈性選購,但也支援更多、更大容量的 NVMe SSD,例如 Dell PowerEdge XE9680 預計在 2025 年推出,將支援最高 16 顆 122.88TB 的 NVMe SSD,代表伺服器可搭載近 2PB 的 NVMe 儲存空間。即使在公有雲端租用 GPU 伺服器,其本地 NVMe SSD 也會內建包含在配置中。
我們都知道本地儲存效能遠優於網路儲存,那麼,為什麼 GPU 伺服器的本地儲存會經常被忽略呢?
主要有三個原因:
- 它是資訊孤島:只有位於同一台伺服器中的 GPU 才能完全發揮本地 NVMe 儲存效能。例如雖可透過 NFS 掛載存取該儲存空間,但若有數十或數百台 GPU 伺服器,則需手動導入與導出大量資料,管理相當複雜。
- 它沒有資料保護機制:預設情況下寫入本地儲存的資料不具備保護能力,這也是供應商多數將其作為暫存用途的原因。即便配置 RAID1 或 RAID10,仍會佔用可用容量,且僅提供有限保護。雖可將糾刪碼檔案系統條帶化到多台伺服器,但此舉會使大多數 I/O 無法留在本地,浪費性能。GPU 伺服器也經常重新設定或重啟,因此並不穩定。
- 資料難以搬移與共享:在數十至數千台伺服器間手動複製資料極不實際,即使能自動化,監控資料位置與狀態依然耗時且易出錯,增加管理風險與成本。
因此,雖然這些本地儲存資源存在,但實務上往往因難以管理與保護而被忽略。
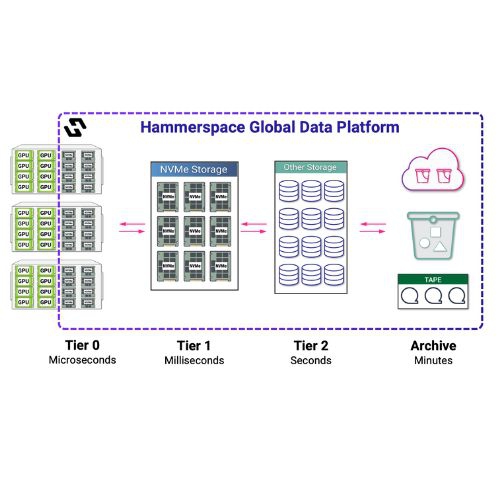
使用 Hammerspace 解鎖「第 0 層」(Tier 0)儲存
Hammerspace 是一套整合分散式檔案與物件資料的資料平台。其基於標準的平行檔案系統架構,能建立跨品牌、跨儲存型態、跨場域與雲端的全球命名空間。平台內建的編排引擎能自動處理資料保護與服務,透過「目標」(政策)在正確時間將資料放置於正確儲存位置。無論資料實體位於何處,用戶端始終可見、可存取,資料在搬移中亦可不中斷操作。Hammerspace 採用開放標準,無須額外安裝用戶端軟體或修改核心,部署簡便快速。
在建構 Hammerspace 全域資料環境時,可將新建或現有儲存裝置(例如 NAS 的 NFS 匯出、Linux 儲存伺服器等)加入為儲存磁區,透過元資料同化達成,無需資料遷移。之後,可建立 NFS、SMB 或 S3 存取介面供用戶端與應用系統操作資料,而資料則依照目標策略自動放置在最適合的儲存磁區中,可針對耐久性、可用性、效能、地點與自訂中繼資料進行精密定義。
Tier 0 成為 Hammerspace 全域儲存的一部分
將每台 GPU 伺服器上的本地磁碟掛載為 NFS 匯出後,這些資源即可加入 Hammerspace,成為 Tier 0 儲存的一環,並享有所有 Hammerspace 的功能與優勢。
- Tier 0 資料不再是孤島:GPU 伺服器本地磁碟一旦加入 Hammerspace 全域命名空間,其上的檔案與物件資料便可被集中管理與跨平台存取,不再受限於伺服器本身。
- Tier 0 資料獲得保護:透過 Hammerspace 的目標政策,資料可被設定自動備份或複寫至其他儲存磁區(包含本地或雲端),達到所需的可用性與耐久性標準。
- Tier 0 資料可被智慧編排:Hammerspace 支援跨階層資料流動。例如,可將最新資料保留於 Tier 0,而將舊資料自動轉移至低成本儲存;或在開機時將必要檔案固定於本地儲存,以避免「開機風暴」造成的延遲;也可將資料暫存於 Tier 0 處理完畢後再分層備份或搬移。
- NFS 協定旁路:最大化 GPU 效能
Hammerspace 不採用私有協定或自製核心模組,而是對 Linux 標準協定進行優化,提升效能並保有開放彈性。例如在 Linux Kernel 6.12 起導入的 LOCALIO 協定,當偵測到 NFS 伺服器與用戶端位於同一主機上時,便可繞過標準資料流程,實現「零拷貝」的極速存取。此創新亦支援容器環境,實現最大化的效能與最小延遲。透過 LOCALIO 協定,GPU 本地存取資料的速度提升最高可達讀取 12 倍、寫入 3 倍,完美釋放 NVMe 的效能潛力。
Tier 0 實際應用:Checkpoint
AI 與高效能運算(HPC)通常涉及跨大規模伺服器叢集的長時間運算作業,一旦中斷可能造成重大損失。因此「Checkpoint」技術被廣泛應用,用來定期將運算狀態儲存至持久儲存中,日後若伺服器故障,可從 Checkpoint 狀態繼續,而非從頭開始。然而,傳統 Checkpoint 操作需將大量資料透過網路傳送至共享儲存,導致 GPU 長時間等待。若使用 Tier 0,本地 NVMe 儲存可直接用於記錄 Checkpoint,配合 NFS 協定旁路功能,可將作業時間從數分鐘縮短至數秒,GPU 幾乎無需停工,大幅提升叢集效能與 GPU 使用率。
Checkpoint 文件可在之後透過 Hammerspace 自動分層備份至其他儲存系統或雲端,資料安全與效能兼得。更重要的是,由於所有儲存位置都在同一命名空間中,Checkpoint 文件始終保持在一致的邏輯位置,無論其實體位置如何變動,系統皆可存取。
Hammerspace Tier 0 的關鍵優勢總結:
- 原生支援 Linux,不需額外軟體或代理程式
- 避免版本相容與維運問題,簡化部署與維護。
- 使用標準協定,與所有主要發行版完全相容。
- 內建資料保護與分層能力
- 本地磁碟可被自動備份至雲端或異地,無需設定 RAID。
- 提供智能化的容錯與版本控制策略。
- 具備智慧資料編排與全域命名空間
- 本地儲存成為全域架構一部分,實現資源最大化與彈性調度。
- 支援多副本資料複寫與本地親和性配置,提升讀寫效能。
- NFS 協定旁路技術最大化 NVMe 效能
- 本地資料存取可避開傳統堆疊瓶頸,達成極速 IO。
- 完全相容標準協定,效能與開放兼得。
Hammerspace v5.1 與 Tier 0 儲存層,將 GPU 運算基礎架構轉型為更具效益的投資平台,不僅提升效能,更大幅縮短成果交付時間,是 AI 時代不可或缺的基礎建設。
📩 如果有任何需求,歡迎與資褓儲存聯繫:Marketing@datasitter.com