

Hammerspace 利用伺服器本地 NVMe 磁碟打造全球共享儲存,在 MLPerf 1.0 基準測試中創下新紀錄
Hammerspace 利用此基準驗證其全新 Tier 0 架構的效能與優勢。此次測試於未啟用計算儲存功能的 ScaleFlux NVMe 磁碟所安裝的 Supermicro 伺服器上進行。Hammerspace 的 Tier 0 測試結果與其他廠商先前提交的基準資料(MLCommons 截至 2024 年 10 月 25 日)進行比較。
Hammerspace 利用伺服器本地 NVMe 磁碟打造全球共享儲存,在 MLPerf 1.0 基準測試中創下新紀錄
MLCommons 組織於 2024 年 9 月發布 MLPerf 1.0 基準測試,Hammerspace 利用此基準驗證其全新 Tier 0 架構的效能與優勢。此次測試於未啟用計算儲存功能的 ScaleFlux NVMe 磁碟所安裝的 Supermicro 伺服器上進行。Hammerspace 的 Tier 0 測試結果與其他廠商先前提交的基準資料(MLCommons 截至 2024 年 10 月 25 日)進行比較。為凸顯 Tier 0 架構的效能優勢,此次採用兩種測試情境。測試為開放組別(Open Division),尚未經 MLCommons 組織審查,預計於下個審查周期提交。
---
測試場景一(2a)
採用四部 Linux 儲存伺服器(見圖)建構典型的 Hyperscale NAS 架構。進行兩次測試,一次以 200GbE,另一次以 400GbE 連接至用戶端。特別指出,這些 Linux 儲存伺服器僅為標準 Linux 系統,並未安裝任何第三方軟體。所有用戶端皆以標準 Linux 系統透過 pNFSv4.2 掛載由 Hammerspace 提供的 NFS 共享,體現 Hyperscale NAS 架構特色。與 Linux 儲存伺服器相同,用戶端也為標準 Linux 系統。與其他廠商的平行檔案系統不同,Hammerspace 不需在用戶端安裝任何特殊軟體即可達成高效能。用戶端與儲存伺服器分別使用 2x200GbE 或 2x400GbE 連網;Anvil 節點則以 2x100GbE 連接,因其僅處理中繼資料傳輸,不涉及資料流通,100GbE 即足夠。(插圖:外部共享儲存測試架構,非 Tier 0 技術)
 ---
---
測試場景二(2b)
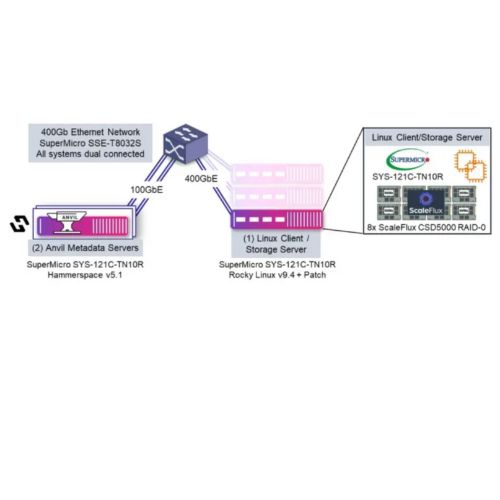
用以展示 Tier 0 技術的效能。測試中由兩台互為備援的 Anvil 中繼資料伺服器處理中繼資料操作。用戶端兼具運行基準測試與儲存伺服器的角色,資料儲存在內建的 ScaleFlux CSD5000 NVMe 磁碟中,並未啟用其計算儲存功能。特別指出,該用戶端僅為未安裝第三方軟體的標準 Linux 系統。內部磁碟透過 NFSv3 導出並以 pNFSv4.2 掛載。中繼資料需經網路傳至 Anvil,但資料傳輸路徑完全保留於主機內部,透過 Tier 0 與 NFS bypass 協定(LOCALIO)實現本地檔案系統的直接存取,此直接路徑大幅提升吞吐量並降低延遲。用戶端伺服器透過 2x400GbE 連接網路;每個 Anvil 節點以兩條 100GbE 線路連接,因其僅處理中繼資料,故已足夠。(插圖:使用伺服器內建 NVMe 磁碟測試架構,Tier 0 技術)

---
硬體配置
Hammerspace Anvil規格(數量:2台)

Linux儲存服務設備規格(數量4台)、客戶端(數量)2台

網路交換設備

軟體配置
上述硬體均使用相同軟體版本:
- Anvil 節點運行 Hammerspace v5.1,包含 Linux 作業系統、應用程式及所有相依項目。
- Linux 儲存伺服器與用戶端皆採 Rocky Linux v9.4,無需額外安裝更新或套件。
- MLPerf 測試程式碼已調整以繞過頁面快取,雖非 Tier 0 必需,卻可額外優化效能。
---
測試成果
- 1 台用戶端(1U):模擬支援 33 顆 H100 GPU,吞吐量 91.8GB/s
- 3 台用戶端(3U):模擬支援 99 顆 H100 GPU,吞吐量 275.5GB/s
僅以一台用戶端,Hammerspace 的效能即超越需 18 台用戶端的 Lustre 系統。當雙方均使用 18 台用戶端時,Hammerspace 效能為 Lustre 的 20 倍!
---
重點說明
Tier 0 技術可突破網路瓶頸
高效能儲存為提升 GPU 使用率不可或缺。測試指出網路速度至關重要:用戶端由 2x100GbE 升級至 2x400GbE 後,可支援 GPU 數量從 7 增至 25,證明 100GbE 已成為效能瓶頸。
最佳方式就是不透過網路
Tier 0 技術利用本地 NVMe 儲存,模擬 GPU 數比透過 2x400GbE 存取外部儲存增加 32%,整體吞吐提升 28%。
效能具線性擴展性
Tier 0 架構讓 GPU 可直接處理本地儲存資料。Hammerspace 可自動調度資料至 Tier 0 並進行備份,再將 Checkpoint 與運算結果卸載至次級儲存層(如物件儲存或磁帶)。由於處理作業皆於本地進行,當更多具 Tier 0 儲存的 GPU 伺服器加入叢集時,效能可線性擴展。
---
Tier 0 可降低資本與營運支出
Hammerspace Tier 0 將現有 GPU 伺服器內建的 NVMe 磁碟納入全域共享檔案系統,排除以往無法使用的限制,帶來下列效益:
- 減少外部儲存投資:採用本地 NVMe 儲存,降低對高效能外部儲存與其配套網路、電力與冷卻設備的依賴。
- 縮短部署時間:Hammerspace 可於數分鐘內啟用既有儲存,節省外部儲存與網路硬體的安裝時間。
- 提升 CPU 使用效率:相較於需安裝私有客戶端的傳統平行檔案系統,Tier 0 幾乎不耗用 CPU 資源,保留更多伺服器資源給業務工作。
- 提升 GPU 效能:Checkpoint 時間由數分鐘縮短為數秒,釋放更多 GPU 運算能力,加快作業完成,無需額外硬體投資。